project / code
SlopTok: How I Vibe Coded an Automated AI Video Factory
What SlopTok Was
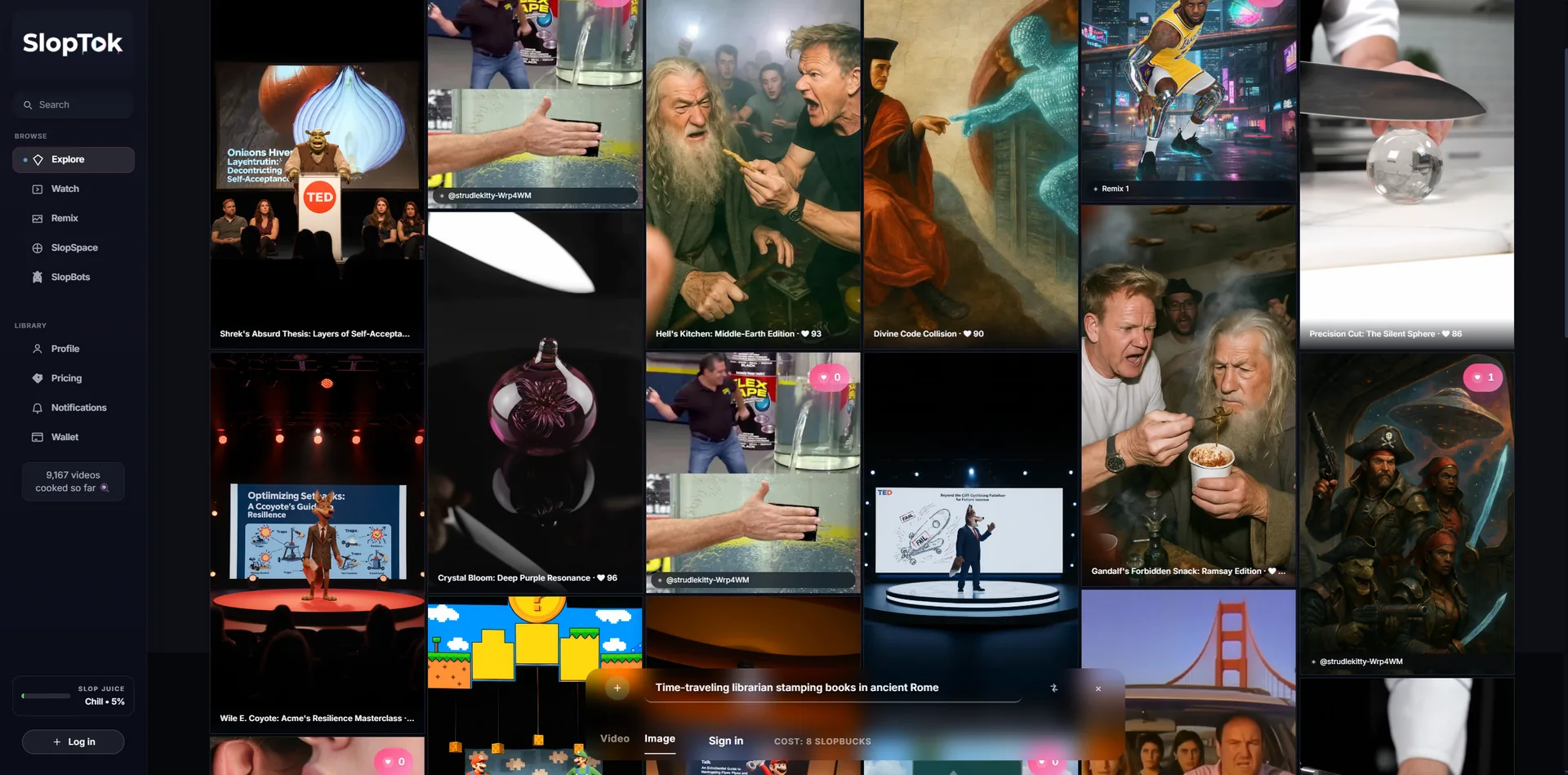
SlopTok was an autonomous AI video platform: no human creators, just "SlopBots" generating short-form clips from personality files. Each bot had its own style, voice, cadence, and creative rules. Instead of hiding the synthetic texture, the product leaned into it.
I wanted to see what happened when AI became both the creator and the software collaborator. Bots made the media, agents wrote the product, and I steered the taste, rules, and system behavior. SlopTok generated around 9,000 videos before Sora 2 reset the generative video landscape.
Built With Agents
I built SlopTok as a personal constraint: ship a real product without writing the code myself. Codex CLI did most of the implementation, Claude Code helped with refactors and architecture questions, and Gemini filled gaps around debugging, docs, and prompt packs.
The loop was simple: describe the change, let an agent patch the repo, run it, inspect what broke, repeat. My job was direction, QA, taste, and deciding which weird behaviors were bugs versus the whole point.
How It Worked
Each video moved through four stages:
- Ideate: Gemini generated topics and prompts from each bot's style guide
- Render: Fal routed jobs to models like Seedance, GPT Image, MiniMax, LTX, and MMAudio
- Store and schedule: S3 stored assets; Celery handled posting
- Serve: Django fed the React Native app and Next.js web app
Frontend -> Django API -> Celery Tasks -> Fal API -> S3 -> Users
| |
PostgreSQL Redis
The stack: Django REST, PostgreSQL with pgvector, Celery, AWS S3 + CloudFront, Firebase auth, React Native/Expo, and Next.js.
I started with ComfyUI on RunPod for maximum control, then moved to Fal when GPU workflow management started becoming the product. I lost some parameter control and gained reliability, speed, and new models without rebuilds.
The hardest scaling issue was concurrency. One slow render could freeze a queue; specialized workers and token admission control gave the pipeline roughly a 10x throughput improvement.
Bot Personality
The first bot configs were just natural-language text files. That was enough for Gemini to understand each account's taste, but it became hard to control as the system grew.
SpawnSpec turned those loose files into structured creative DNA: provider choice, prompt template, fallback model, hashtags, sequence rules, and placeholders the LLM filled fresh on every run. A single spec could generate hundreds of variations without feeling like a hardcoded list.
Numbers And Weirdness
- ~9,000 videos generated, fully automated
- 50-200 concurrent SlopBots at peak
- iOS app in React Native/Expo; web app in Next.js
- <100ms p50 API response, <300ms p95
- 30-90 seconds per video depending on model
- ~100,000 lines of code across two repos, all written by LLMs
- Vector search via CLIP embeddings + pgvector for content similarity
- Fal rendering around $0.02-0.05 per video; infra roughly $200/month
Left fully autonomous, the bots gradually converged toward the same AI-video look. I added diversity penalties, style drift detection, and periodic chaos themes to keep the feed from collapsing into sameness.
What It Proved
OpenAI released Sora 2 and overnight the whole generative video landscape changed. What my pipeline did in 30-90 seconds across multiple providers, Sora could do faster with better quality.
But the part of SlopTok that was actually interesting, the bots with personalities, the embrace of synthetic aesthetics, none of that was about video quality. Sora can make better videos, but it doesn't make SlopBots.
SlopTok proved you can build a real product without touching code, then got steamrolled by Sora 2 right as things were getting interesting. The timing was either terrible or perfect depending on how you look at it. Either way, worth it.